2020年6月6日,中国计算机学会(CCF)主办的中国计算机学会青年精英大会(CCF YEF)在线上举行,在“经典流传的机器学习与数据挖掘算法”技术论坛上,瑞莱智慧RealAI首席科学家、CCF高级会员、清华大学计算机系长聘教授朱军做了题为《贝叶斯学习回顾与展望》报告,总时长为1个小时左右,内容主要分为五个部分:贝叶斯理论应对不确定性、贝叶斯理论和经典算法、可扩展的贝叶斯方法、珠算编程库以及应用贝叶斯理论的一些例子。
下文是本场报告的文字版,由 AI 科技评论编辑。
为什么要用贝叶斯做机器学习或者人工智能?主要因为“不确定性”的存在。首先是处理对象的不确定性,例如无人驾驶,其环境和系统就存在很多我们未知的随机因素。

再例如对抗样本研究(恶意干扰产生的不确定性),如果在一张图片中加上少量的噪音,虽然展示效果对人眼没有影响,而足以让人工神经网络产生误判。
另一个不确定性来自模型方面。现在的模型“体量”越来越大,一个经典的模型甚至达到了十亿规模的参数,而最近,包含上千亿参数的模型也已经出现。
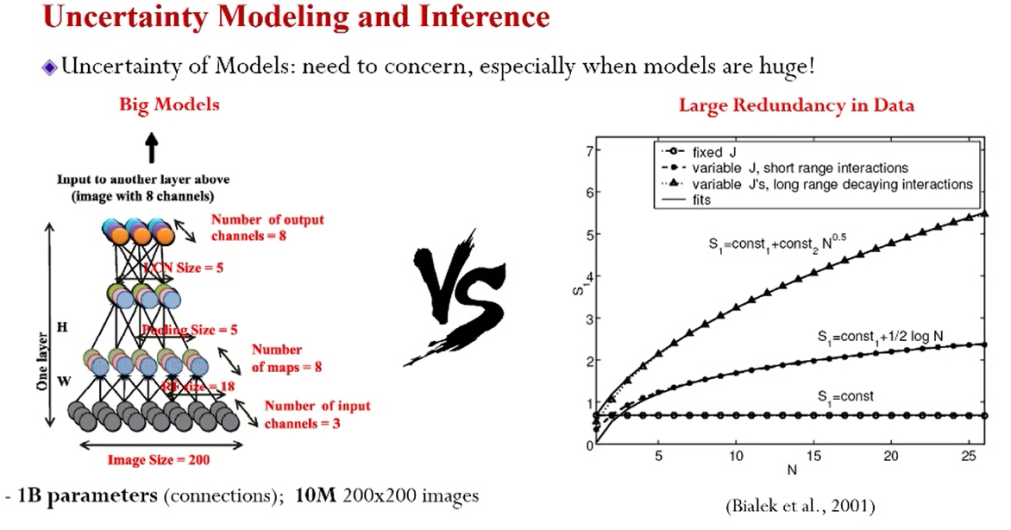
所以模型已经足够大,训练的重点应该在于数据量有多少。如上图所示,右边三条曲线刻画了“有用”信息的增长速度,其中最快的增长速度为N的1/2次方。这反映的事实是,有用信息的增长“跟”不上模型体量的增长速度。这种形式模型的不确定性,直观的体现为过拟合的现象。
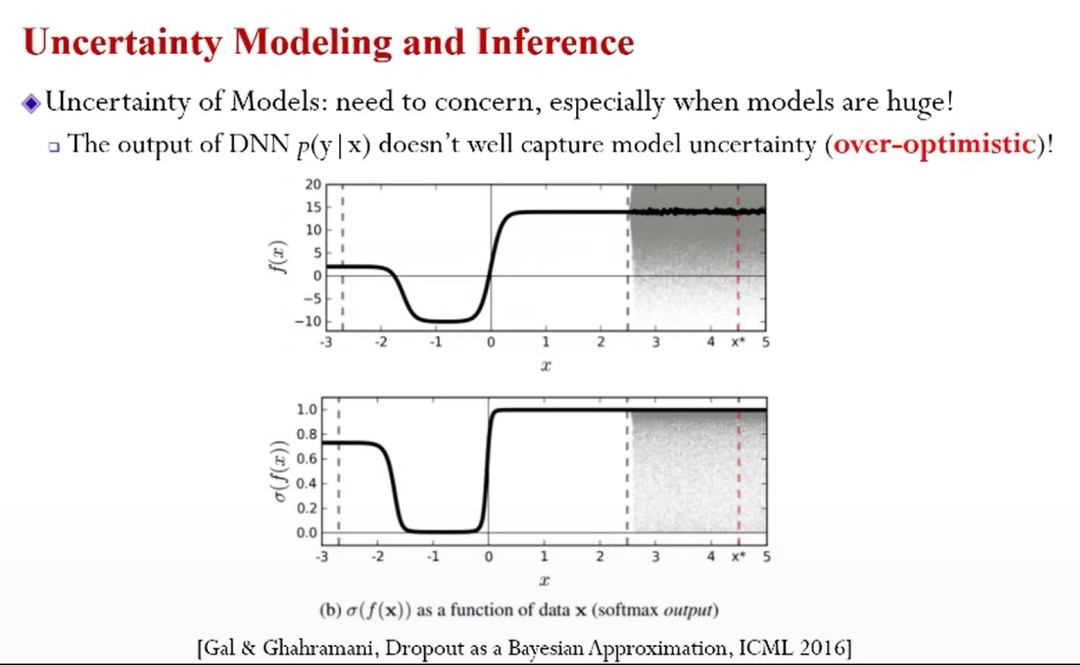
通常模型给的输出(例如深度神经网络)往往是一个概率,研究员通常把此概率解释成置信度。而实际上并不能反映不确定性的因素,这种度量也过于乐观。
举例而言,如上图,白色区域是可以观察到的训练数据,右边灰色是无法观测到的数据,如果用观察到的数据做训练,会得到一个表现(拟合)优秀的曲线。而实际上的预测的任务是将曲线外延(延伸到灰色区域),也即所预测的数据偏离了训练数据,这会带来“很高”的不确定性。
针对上述不确定性,传统模型无法有效应对。

那么面对这一类的不确定性应该如何建模?核心是用概率的方法,也叫贝叶斯方法。原理很简单,如上图所示,中间的那个公式就是贝叶斯公式。此公式包含先验、似然函数以及后验分布。没看到数据之前,模型有先验(π(θ)),有了数据之后,建模得到的是似然模型(P(D|θ)),有了这两个因素可以根据贝叶斯定律计算后验概率(P(θ|D))。
如果追溯历史,最早在1763年就有文章讨论贝叶斯理论,正式发表则是在贝叶斯去世之后。而目前机器领域内有贝叶斯方法和非贝叶斯方法之争,总体来说在社区内共处得还算融洽。2015年nature也发表了一篇文章《Probabilisticmachine learning and artificial intelligence》详细阐述了关于概率的机器学习以及人工智能里边的一些核心的问题、思想等进展,感兴趣的可以去阅读。

经典的方法从Naive贝叶斯开始,上图是形式化的描述。作为一种简单贝叶斯模型,其假设给定标签变量(Y)的情况下,其输入特征是条件独立的。例如,大脑中想象一只鸟,那么就会联想其特征是:飞行、羽毛、腿等等。
上述“联想”的过程可以用贝叶斯建模,通过定义联合分布,运用贝叶斯公式,可以得到在给定输入特征(X)的情况下得到“标签(Y)”的后验分布(编者注:像不像高数中的条件概率公式☺),有了后验分布然后就可以做称作贝叶斯决策的最优决策。
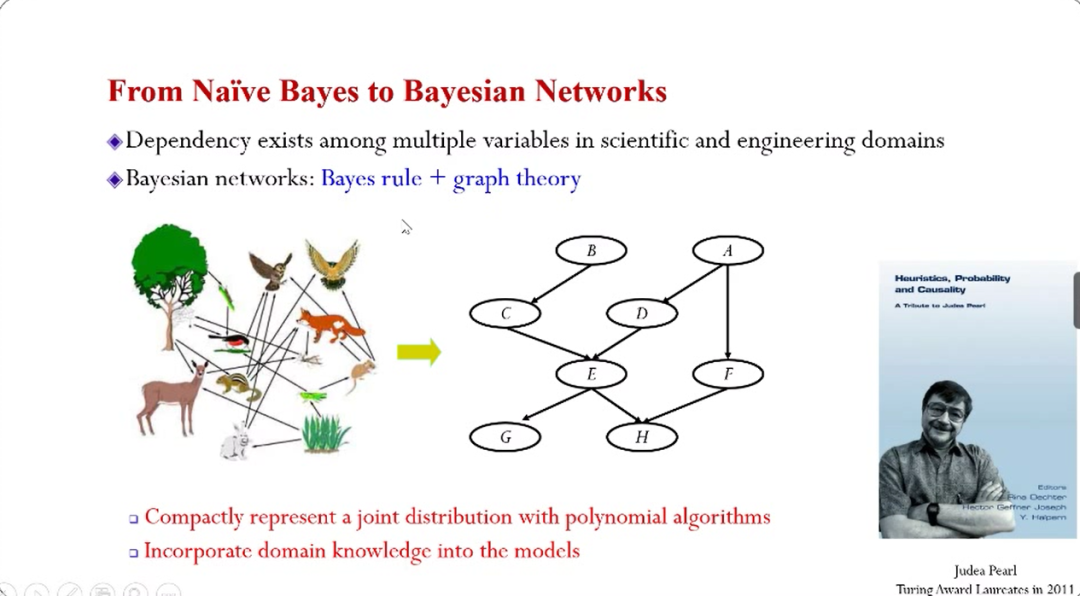
Naive贝叶斯之后非常重要的一种扩展是贝叶斯准则和图论的结合,也即贝叶斯网络。例如食物链,上面很多物种之间存在依赖关系,这种关系并不是随机无规律的,其规律已经被生物学家洞察。所以,食物链的关系(联合分布)就可以用右边稀疏连接的图来简洁刻画,图上的每一个节点都是随机变量,线代表了点之间的关系,这种点与线之间的结构清晰表达了多个变量的联合分布。这种图结构的表达方式将指数级别的参数需求降到了多项式级别,同时也将专家的知识纳入到模型里。所以,贝叶斯更像是一种非常强大的建模语言。
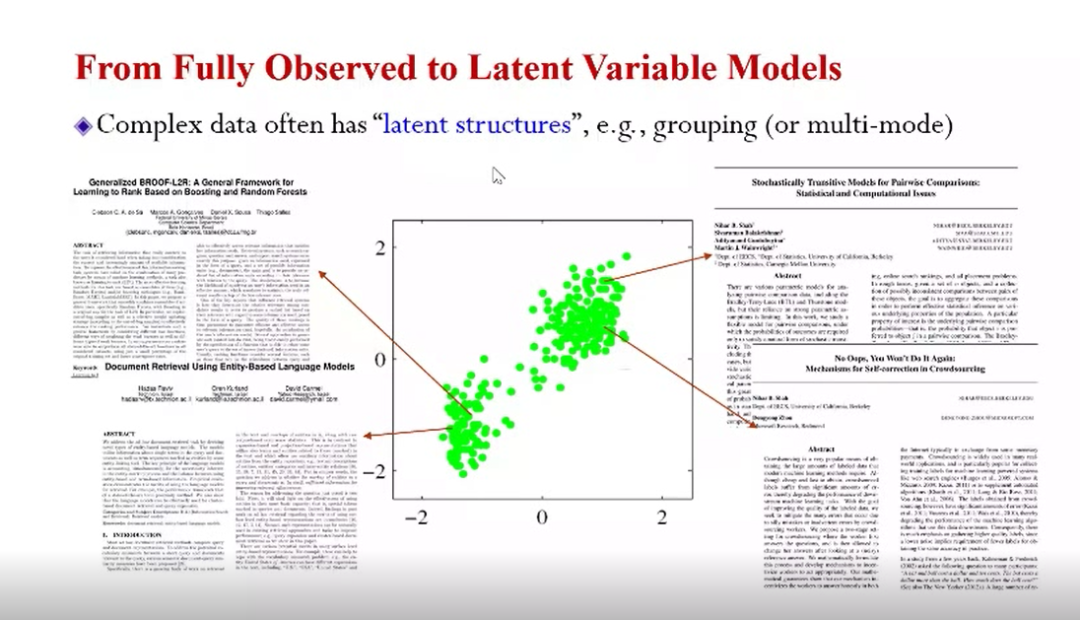
另一个非常重要进展是从完全可观测(fully observed)到隐变量的模型变化。完全可观测是指所有随机变量的取值,在训练数据里都是完全可获得的。考虑到实际情况,并不是如此“完全”,例如对上图文档集合进行分析,用语言模型进行建模时,会发现数据之间存在复杂的结构(例如不同类的文章用词不同),这些结构在训练集中无法直接观测,这种无法直接观测到的变量被称为隐变量。

对于上面这个例子,我们可能会引入一个变量去表示,从而找到某一文档从哪一个会议中来,即可能来自SIGIR也可能来自ICML,对于不同的会议论文,如果用不同的语言模型进行描述的,就能准确刻画它们不同的风格。这种想法可以用上图右边所示的概率图模型进行描述。先对隐变量有一个先验分布,然后给定这个隐变量,再用相应的语言模型进行定义X,如此便能进行推断。也即给定观察到的X,就能找到“它”属于哪一类的文章。
这里实际上还有一个重要的问题,即这个参数从哪来?例如在语言模型里,它的参数怎么学习?
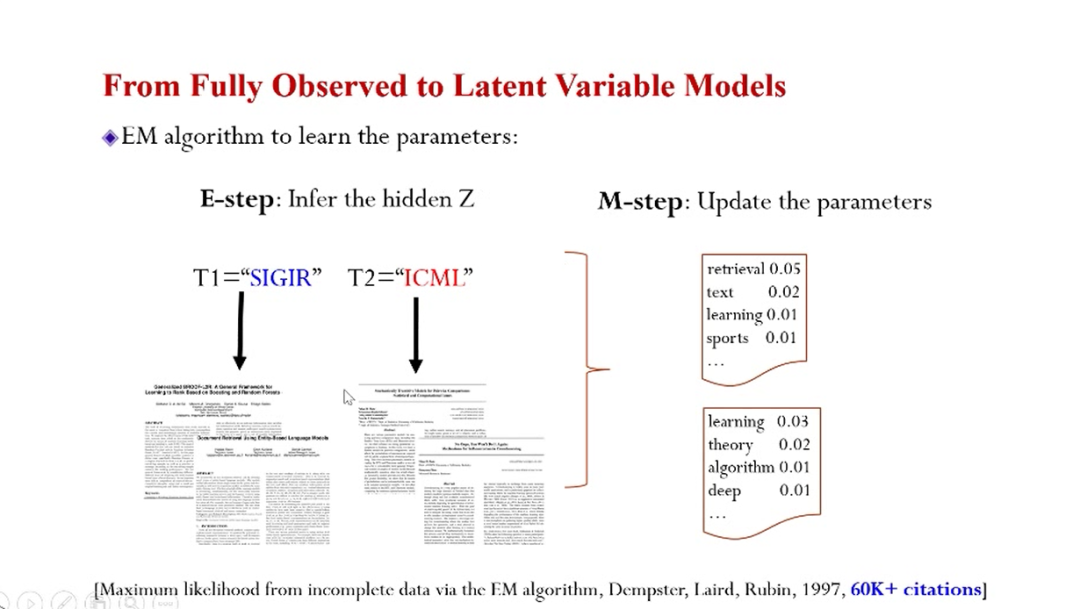
对于这种有隐变量的模型,有一个非常经典的EM算法,对于不能观测到的变量(隐变量)添加了E-step,即进行用概率推断的方法估计隐变量,然后基于估计的信息就可以在M-step里更新模型的自由参数。
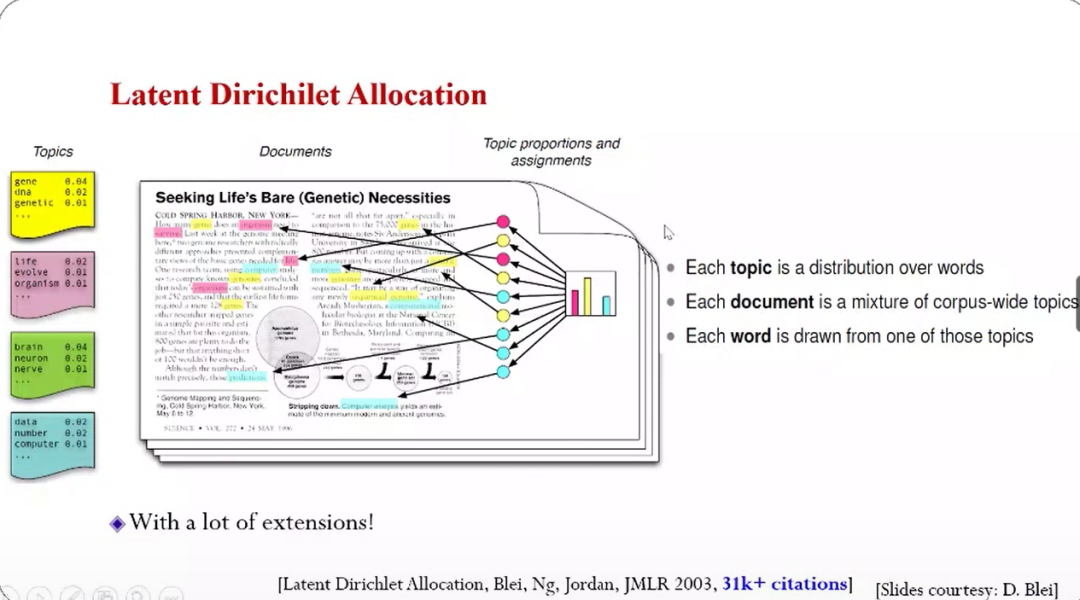
针对文本建模,另外一个重要的方法是LDA(LatentDirichlet Allocation),这个模型有两层隐变量,一层是文档级别的,即对多个主题有多个混合概率;第二层是对word本身的,即对每个单词有一个特定的主题。

另外,关于贝叶斯理论还有一个更加普遍的解释:与机器学习里的优化问题结合起来,将贝叶斯推理过程等价成一个最优化的问题,例如最小化一个目标函数,然后添加一些简单的约束,在优化过程中也可以把先验信息、数据等内容考虑进来。
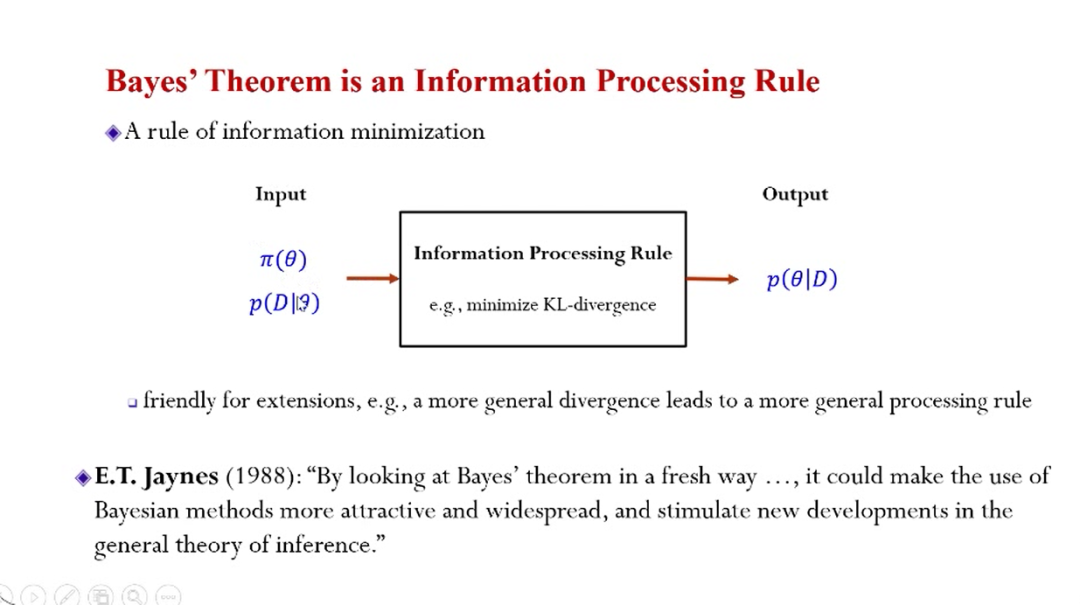
更加直观抽象一些,可以用信息处理的过程进行描述:输入先验分布、数据的似然,然后通过某种准则的信息处理,得到后验分布的输出,其中,后验分布包括输入的所有信息。这种观点是一般性的信息处理的准则,实际上这种准则可以比较灵活定义。
这种基于优化的解释,实际上在上世纪80年代就有统计学家提出过,E.T. Jaynes是比较有名的统计学家,对我们前面讲的优化解释做了一些comments,它给经典的贝叶斯提供了一个新颖的解释,可以让贝叶斯方法更广泛被应用,而且激发了新的发展。

基于这种信息处理过程的优化思想,2014年的时候,我们曾经对贝叶斯定理本身做了一个推广和泛化——正则化的贝叶斯推理(RegBayes)。核心的思想是对后验分布(q)直接进行性质约束,例如定义后验分布在某些分类任务上的性能。这种灵活的建模框架能够完成推理与凸正则化所需的post数据后验分布。当凸正则化是诱导从线性算子的后验分布,可以用凸分析理论求解RegBayes问题。
在RegBayes的框架指导下,发展了一系列优秀的算法,包括将最大间隔准则融入到贝叶斯推理、将知识(如一阶谓词逻辑表示的知识)融入到贝叶斯推理中等。
当前的可扩展的贝叶斯机器学习有两个方向,一个是在人工智能或者深度学习火之前,针对大数据的处理发方法。
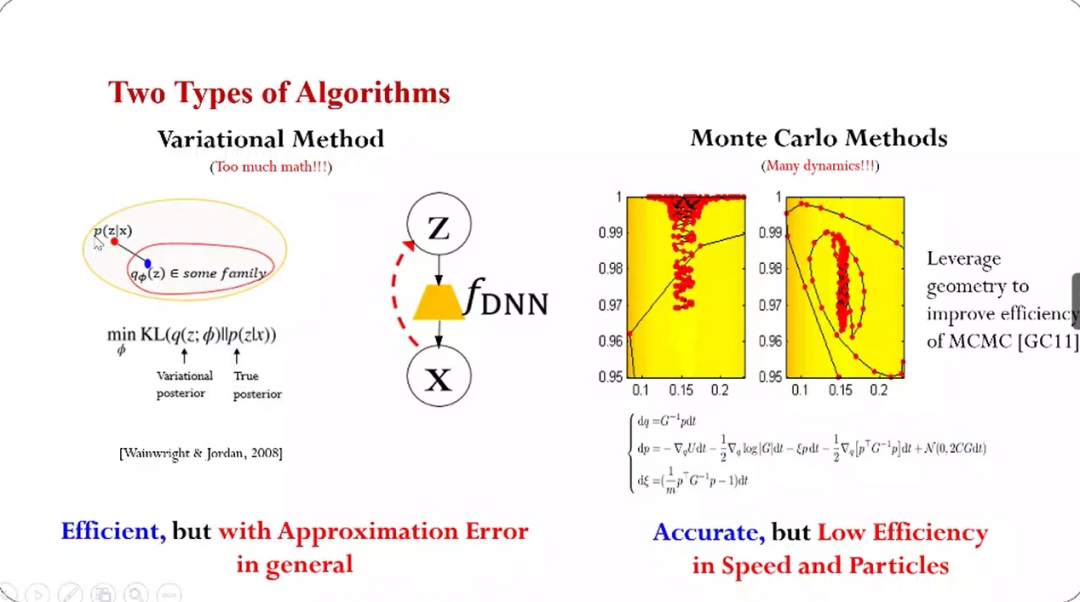
在算法层面,概率机器学习最主要有两类算法,一种是变分的方法,其背后也是EM算法的思想。因为直接计算后验分布非常困难,所以变分法的操作手段主要是找“近似”,例如假设有一个简化的概率分布q,这个q在某个分布的子集里面,然后通过一个最优化的问题来找到一个最优的逼近。这种方法实际上是将推理的问题和优化结合在一起,所以就会用到很多的比较先进的优化技巧,可以让变分方法非常高效。
但是这种方法的天然缺点是:如果子集定义不准确,可能会带来近似误差,而且这种误差实际上消除不掉。
和变分法对应的是蒙特卡洛方法,其采用随机采样的思想,如上图右边所示模拟粒子的演化的过程:粒子不断演化,最终如果模拟时间足够长的话,就会收敛到想要的目标分布。这里也有很多挑战,例如模型参数非常多,那么它的维度就很高。
蒙特卡洛方法在理论上可以保证是精确,但是效率是比较低,体现在两方面:一是收敛速度比较慢,二是粒子的利用效率比较低。
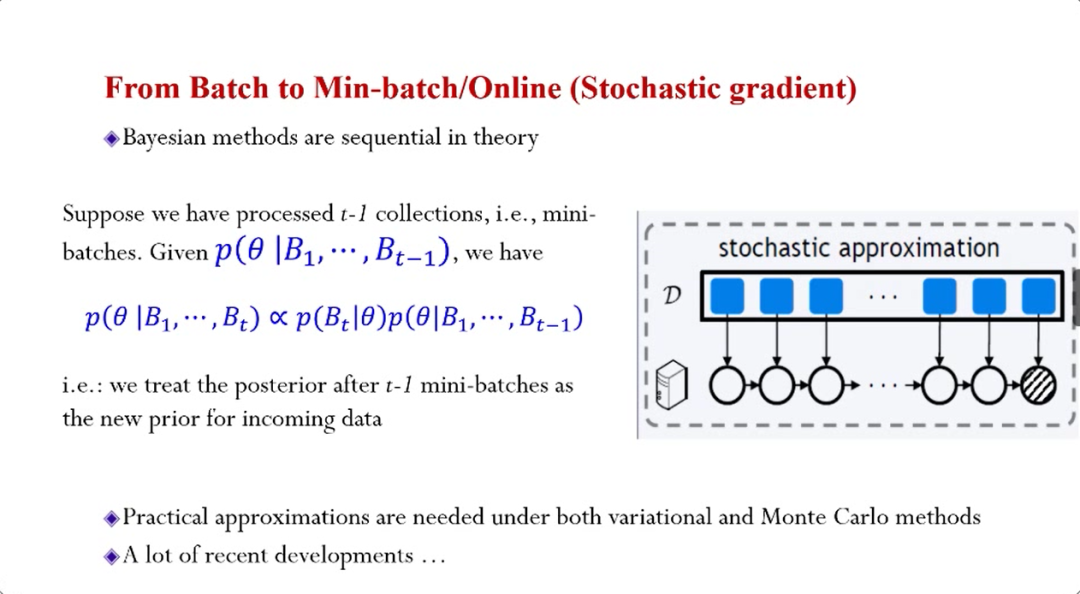
所以在大数据的场景下,大概有两个方面的发展,一是从处理Batch到处理Mini-batch,贝叶斯方法在理论上非常适合处理这种“流”数据或者是Online推断,由于每一步的后验分布并不能精确的计算,所以发展了许多近似方法。
二是从集中计算到分布式。贝叶斯定理本身非常适合分布式,当数据分布在多个机器上,可以对每个局部的数据进行后验推断,然后再将后验分布集中起来做简单运算,就可以得到整体精确的经验分布。这种方式在理论上非常漂亮,但是在实际中不可对每一个局部的后验分布进行精确计算,因此发展了很多分布式的近似算法。

第二个可扩展的贝叶斯机器学习方法是处理人工智能相关问题。这个方向下有两个主题,一个是用贝叶斯做深度学习(Bayesian Deep Learning),另一个是用深度学习做贝叶斯(Deep BayesianLearning)。
贝叶斯方法和深度学习方法的“联姻”可以追溯到上世纪90年代的甚至更早,当时大家主要研究的是如何用贝叶斯方法进行神经网络的计算,或者进行神经网络结构的选择。当时面临的困难和主要问题是数据缺乏和计算能力不足,所以很多神经网络训练的深度非常的浅。
例如David MacKay(其导师是John JHopfield)的博士论文就是用贝叶斯方法进行神经网络结构的选择。论文中提到的一个结论也非常有名,即做贝叶斯一定程度上可以等价奥卡姆剃刀准则。

另一篇博士论文来自R.M. Neal(其导师是Hinton),他在论文中提到的一个非常漂亮的结论是:如果对神经网络来做贝叶斯计算,在一定条件下,整个的模型会变成高斯过程。这个结论把机器学习和概率论关联在了一起,从而促进了概率论在机器学习中深入的研究。
当然这不是故事的全部,随着深度神经网络变得越来越深,可以到处看到贝叶斯方法的身影,比如Dropout,让我们在训练的时候随机丢掉一些边或者丢掉一些结点,然后在更新的时候不进行更新。
但当Hinton最早提出Dropout的时候,并没有解释Dropout如此有效背后的原理。2016年ICML有一篇文章提到:实际上Dropout是在做近似的贝叶斯计算。同样基于这种理解,有一个更准确估计预测置信度的方法,叫MC-Dropout。即通过多次采样的话,可以得到一个更精确的估计,但这个估计还是会存在一些误差。
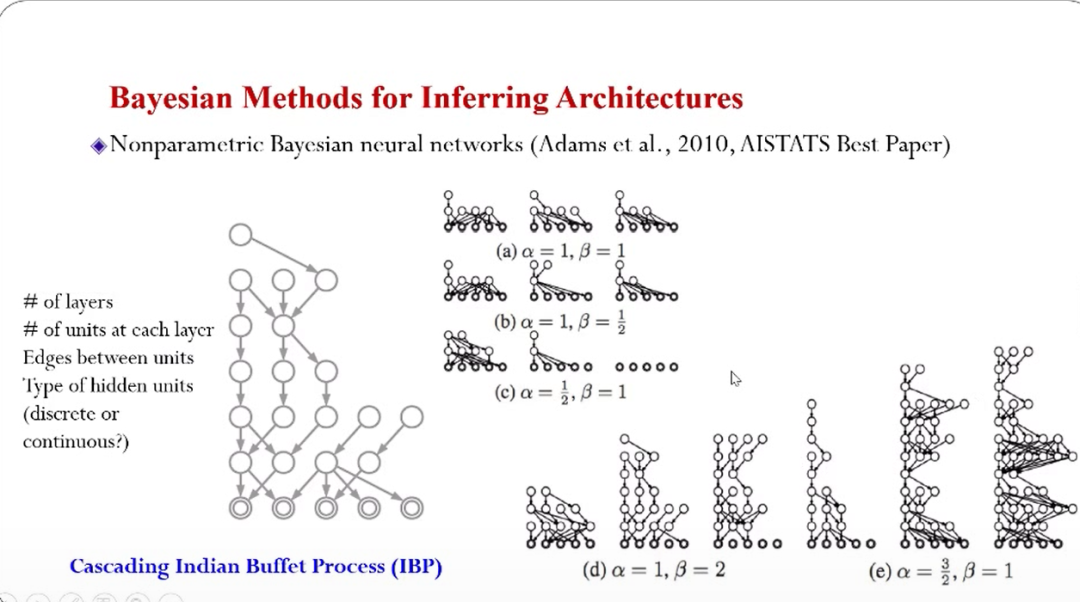
另外,在神经网络结构搜索层面,10年前就有学者研究怎么用贝叶斯的方法生成神经网络的结构,当时用的技术叫做非参数化的贝叶斯,它在理论上是非常优雅的随机过程,可以随机刻画神经网络结构的生成的过程,例如神经网络的层数,每一层的神经元的连接方式等等都可以用随机过程刻画。然后从随机过程中进行采样,每一个样本就对应一个网络结构。当时的一些例子如上图。
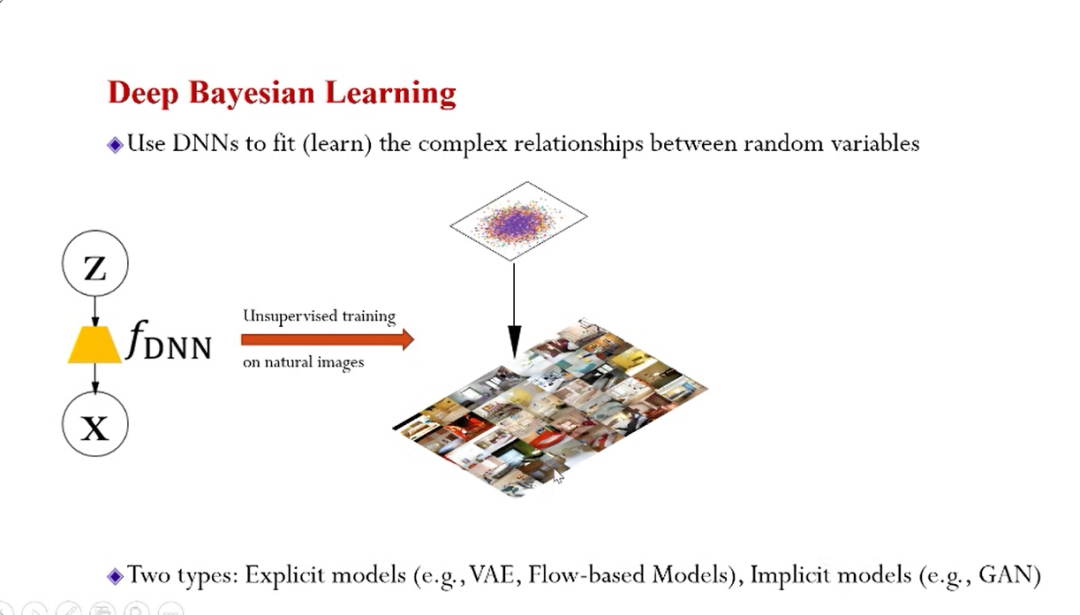
上面的几个例子都是用贝叶斯研究神经网络,那么如何用深度神经网络做贝叶斯学习呢?如该图示意,一些简单的随机变量(如均匀分布或标准高斯),经过函数变换之后得到的随机变量的分布可能“形式各样”。所以变换函数如何获得是重点,在机器学习中思考的是这个变换函数能不能学习获得?
当前深度学习的方法是将这个函数定义为一个神经网络,然后赋予变换函数以神经网络强大的能力,然后在用数据驱动神经网络的训练。如上图右所展示,可以将白噪声(无信息)输入神经网络进行变换,然后得到信息丰富的图片。
这种方法现在叫做深度生成模型,例如GAN、VAE、基于Flow的模型等等。这类模型在机器学习里被研究了很多,大概可以分成两类,一种叫显式的模型,一种叫隐式的模型。显式的模型对数据产生的过程有明确的概率函数刻画。隐式的模型不关心概率函数长成什么样子,只关心样本变化产生的过程,例如GAN就是一个典型隐式的模型。

讲完建模和算法,接下来讲如何去编程。如果对贝叶斯计算和概率进行建模,不光需要关心映射,还要关心数据里不确定的因素,所以这对传统的编程框架有了新的这种要求。
大约在2013~2014年的时候,机器学习领域就在发展深度的概率编程的框架,我们组也做了“珠算”( https://zhusuan.readthedocs.io),是最早的深度概率编程库之一。作为一个构建于 TensorFlow 之上的用于生成模型(Generative Model)的 Python 库。和现有的主要为监督式任务设计的深度学习库不同,珠算的特点是其在很大程度上根基于贝叶斯推理,因此支持各种生成模型:既包括传统的分层贝叶斯模型,也有最近的深度生成模型。

具体操作举例:首先要对数据建模,define一个model,此model实际上是用贝叶斯网络进行描述,在里面还可以像画图一样添加节点,每个节点可以是随机的,也可以是神经网络。最后返回的是一个贝叶斯网络的对象。
珠算里也支持了变分和蒙特卡洛两大类的方法,包括了现在最主流的推理算法。珠算里也有很多已经实现的模型,比如像比较经典的 topic model、矩阵分解、贝叶斯高斯过程、卷积操作等等。
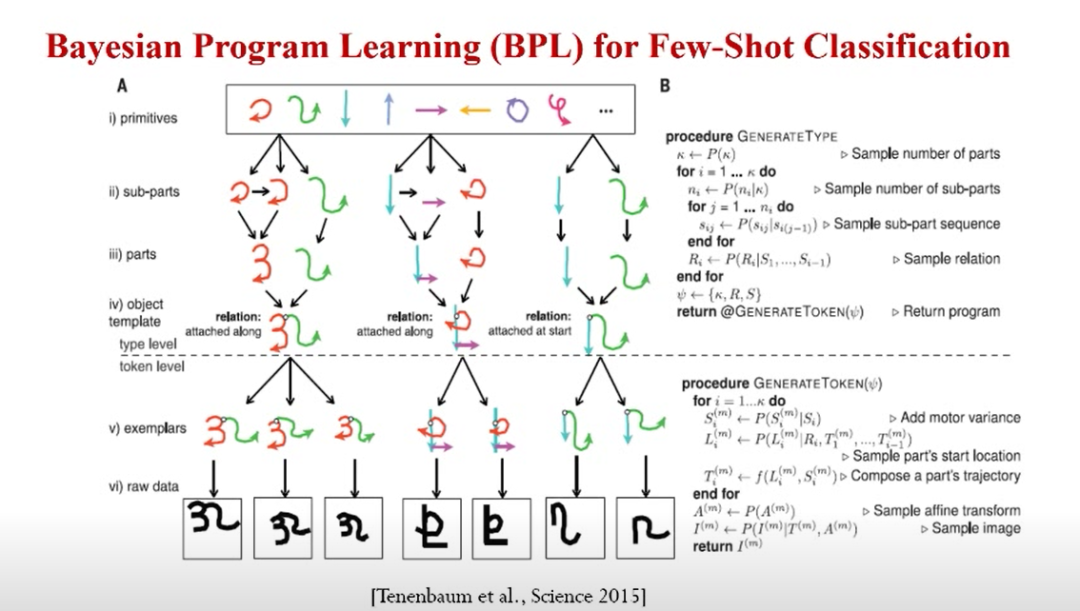
上面是MIT做的一个例子,主要针对小样本学习,当时MIT用贝叶斯建模的方法叫Bayesian Program Learning。其内涵是一个多层的贝叶斯模型,能够用一些基本的部件通过某种组合得到一些更大的部件,然后再在进行某种关系的组合,最后去用噪声渲染模型生成手写字符。
所以整个字符生成过程用贝叶斯的方法刻画了出来。此模型已经引入很强的领域知识,所以在训练的时对数据的依赖就没那么强。甚至模型只观察一个样类(one-shot),就可以做到比较精确的分类。当时展示的效果也是超过了人类的精度。
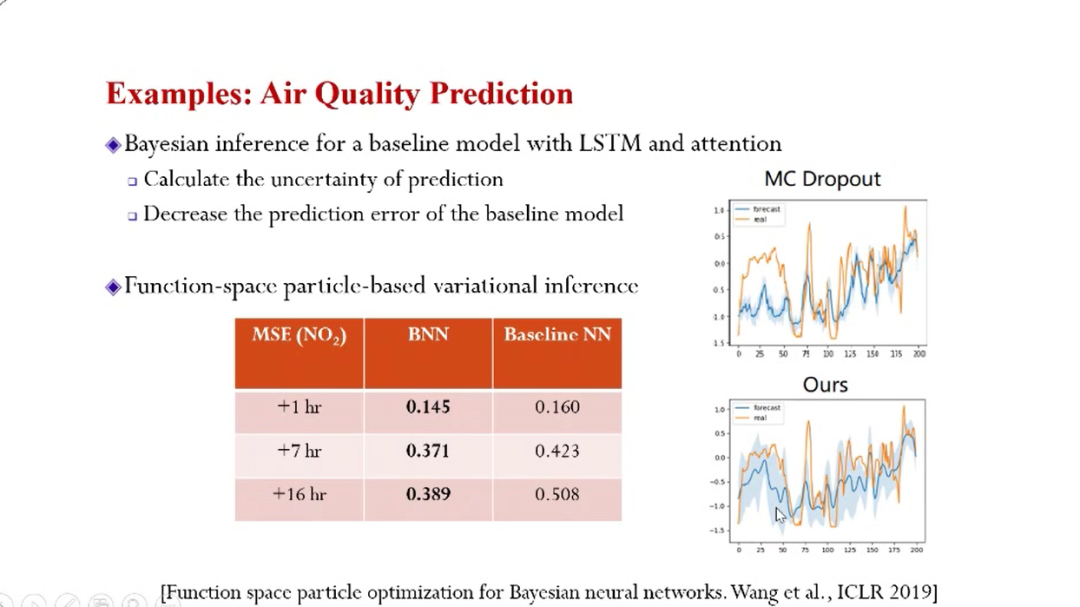
上图的例子是关于预测不确定性的,最初做这个项目最主要的是想计算预测的置信度,即用贝叶斯估计预测的区间。最后的效果是预测的错误率也显著下降。
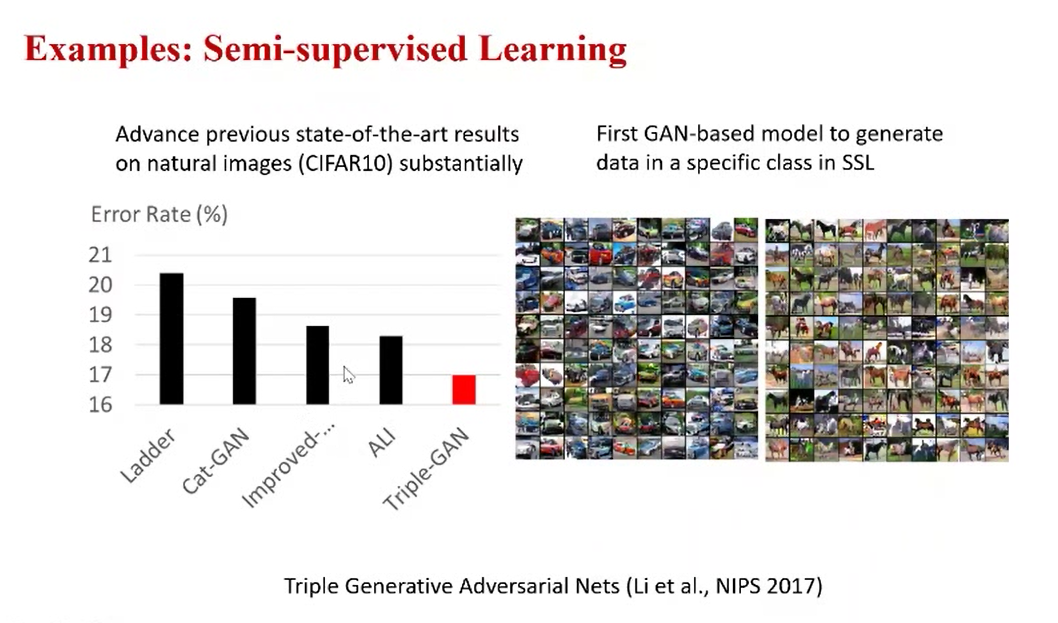
上图例子也是关于半监督学习的,针对如何有效地利用未标注数据得到更好的分类器。这需要对未标注数据进行概率建模,我们当时做了一个叫Triple-GAN的工作,在有完整理论加持下,效果显著。
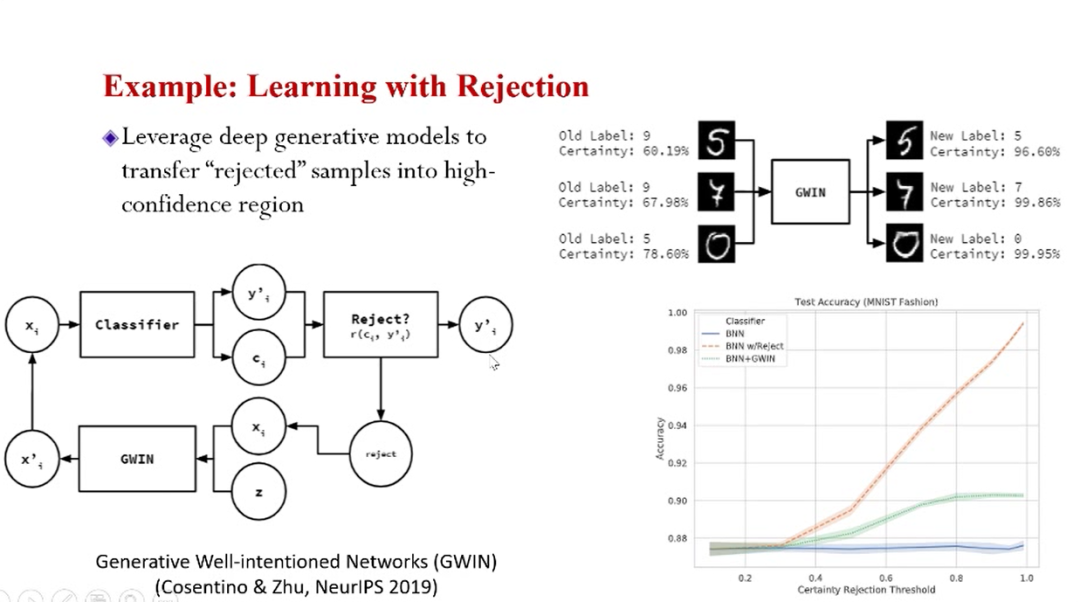
上图的算法可以在遇到不确定或者是很难的样类时选择拒绝。这种“拒绝”的功能传统算法是做不到的。贝叶斯加持下的置信度计算可以实现这种功能。同时,我们可以对“被拒绝”的样本进行变换,得到一个新的样本,同时提升它的分类精度和置信度。
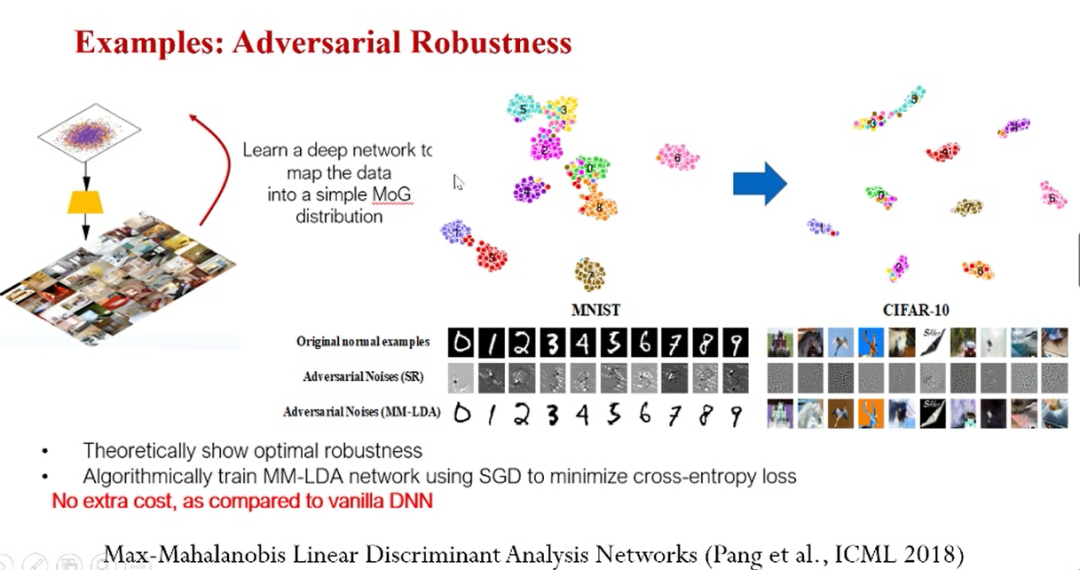
上图的例子是报告开始的时候提到的对抗性样本,即向真实样本中添加人眼不可见的噪声,导致深度学习模型发生预测错误的样本。在ICML2018 的一篇论文《 Max-Mahalanobis LinearDiscriminant Analysis Networks》,我们定义了一种特殊的高斯混合分布MMD,并且理论性地证明了如果输入分布是 MMD,那么线性判别分析(LDA)对于对抗样本有非常好的鲁棒性。基于这一发现,论文中提出了 MM-LDA 网络。简单而言,该网络将复杂的输入数据分布映射到服从 MMD 分布的隐藏特征空间,并使用 LDA 做最后的预测。
最后总结:我们首先明确了做机器学习或做人工智能,其中有很重要的因素是要考虑不确定性,因为方法不管是怎么开发出来的,最终的应用的环境一定是开放的、未知的环境。贝叶斯的方法实际上提供了一种非常强大的语言。贝叶斯实际上代表了一类的思想,从编程的角度来看,这实际上是一种编程的范式。
在报告中我也分享了如何用贝叶斯方法处理大数据,包括和深度学习、深度神经网络融合的最新的进展。
也提到了珠算这一深度的概率编程的:珠算基本上能够实现了现在最好算法以及一些常用的模型。
最后讲了一些实际的例子,即用贝叶斯方法到底可以解决什么样的问题。