发展第三代人工智能是一项非常长期的任务,人工智能的安全和治理也是长期的任务,安全问题是由算法本身引起,彻底解决有很长的路要走。
作者|维克多
编辑 | 青暮
8月3日,首届全球数字经济大会在京召开。在人工智能产业治理论坛上,来自我国人工智能领域的顶尖科学家,围绕主题“探索创新、共举担当”展开前沿对话。
其中,中科院院士、清华大学人工智能研究院名誉院长张钹做了《人工智能的治理与创新发展》的演讲。在演讲中,张钹介绍了实现下一代人工智能的两个范式,其中“所有的处理都在连续空间里进行”的范式一,优点是计算机处理方便,缺点是当知识转为向量表示形式时,丢失了大量语义。
以“打通离散空间和连续空间”为特征的范式二,其优点在于能够从根本上实现第三代人工智能,但缺点在于难以进行模型表示和模型获取。
以下是演讲全文,AI科技评论做了不改变原意的整理(本文经张钹院士确认):
张钹:今天演讲的主题是《人工智能的治理与创新发展》,介绍第三代人工智能的必要性以及目前两种探索途径。
其实,在信息产业发展与技术发展过程也出现过安全性的问题,但信息系统安全性的问题主要来自于大型软件设计上的漏洞或者缺陷,所以相对容易克服。如果发现漏洞只要“补上”就能解问题。

人工智能技术发展到今天,也出现了一些全新的安全问题,但根源不在系统设计方面,而是来源于算法本身的不安全性。因此,解决人工智能的安全问题,必须从算法本身出发,彻底改变,才能让使用者放心。因此,人工智能的安全涉及的因素更加本质,也更难以克服,需要从两个方面入手。
一个方面是治理,治理有两个含义:一是防止人工智能技术被无意识地误用,因为人工智能算法的不安全性很难被预先发现的或者觉察,所以在使用过程中会出现很多错误,如果我们在使用的过程中不注意到这个问题,就会产生无意识的错用,造成非常严重的后果。
第二类问题是有意识地滥用人工智能技术,即恶意对人工智能系统进行攻击或者滥用,这必须通过法律和法规解决。
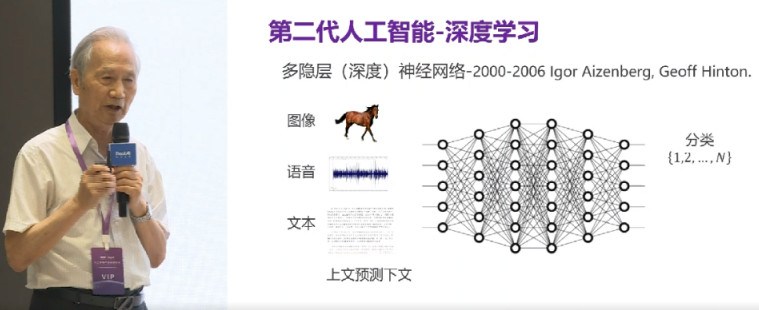
今天我主要讲算法的不安全性,即如何通过技术的创新解决人工智能算法的不安全性问题。也就是我们提出来的,发展第三代人工智能的思路。算法的不安全性来源于第二代人工智能,其特征是数据驱动。图像处理、语音识别、文本处理等任务在“深度学习”和“多样性的数据”的加持下,系统效率非常高。但本质问题是算法非常脆弱。

如上图所示,这是一个图像识别的例子。一张雪山的图片,加上一点点“噪声”,人类仍然认为是一座雪山,但计算机却误认为一条狗,且置信度为99.99%。从这个例子中,我们不仅看出人类和计算机识别机制的差别,也力证了算法的脆弱性。

原因何在?在于黑箱算法本身。如上图所示,计算机并不知道马在哪儿,之所以能准确识别,其采取的机制是:提取局部特征。换句话说,并不是提取马本身的语义特征,仅仅通过提取图片的底层特征进行区别。
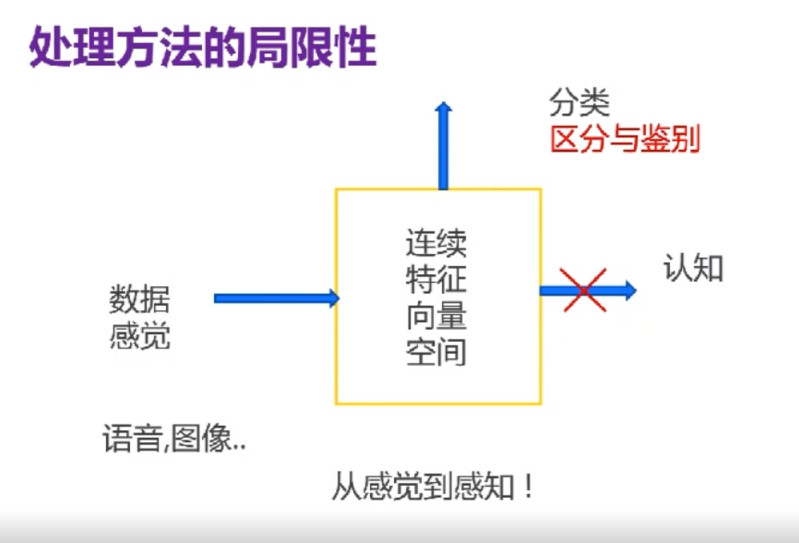
上述两个例子都证明了一个观点:根本性的原理出现了问题。更通俗一些,这种处理方法的局限性表现在:对于图像,我们完全将其放到特征向量空间中,放到连续数据空间中进行处理和分类。因此,算法并不是从认知层面识别物体,而是用分类的方法区分物体。

基于上述缺点,我们提出第三代人工智能,建立可解释的鲁棒人工智能理论。人工智能发展至今,几起几伏,进展非常缓慢,根本原因是没有坚实的理论基础。这与信息科技的发展完全不同,由于其有完备的理论,所以发展非常迅速。我们必须建立人工智能的理论,这才能开发出可信、可靠、可信及可扩展的人工智能技术,从而推动进一步发展。
第三代人工智能的一个核心是知识驱动和数据驱动相结合,充分发挥知识、数据、算法和算力四要素的作用。四个要素,知识当先,其重要性大于数据。
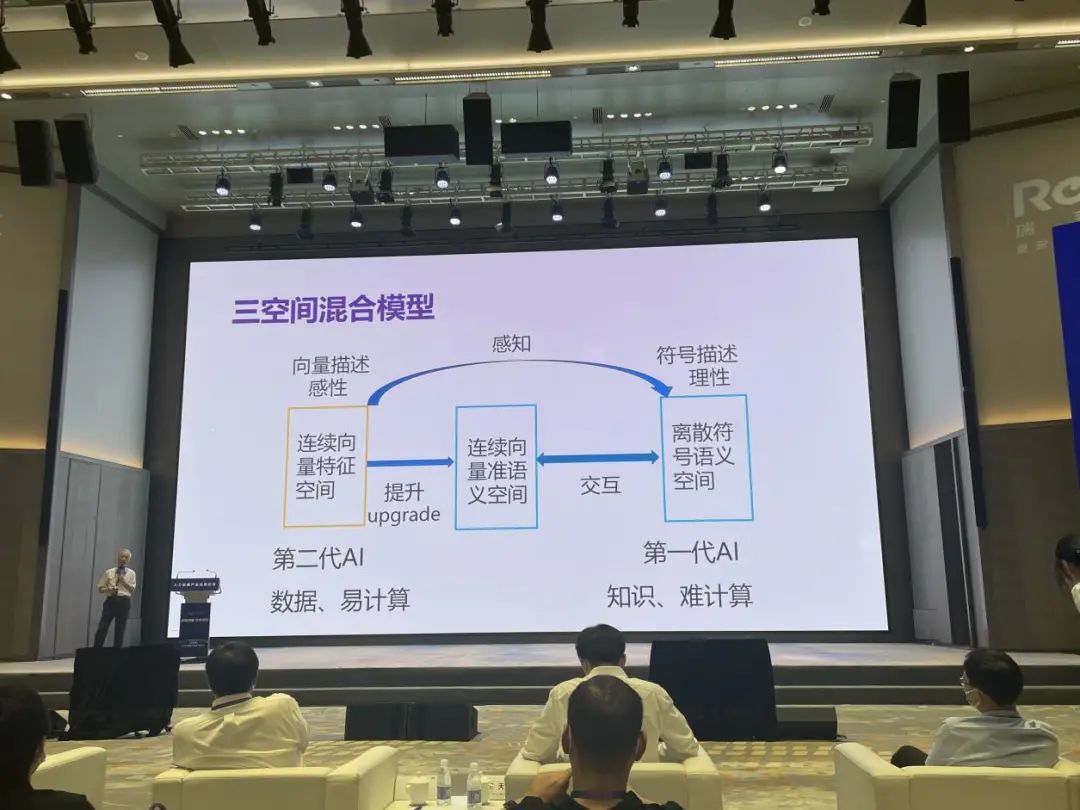
在知识驱动的思想下,我们提出三空间混合模型,打通“第一代人工智能在离散符号空间里处理知识(语义、符号)”和“第二代人工智能在连续空间里处理数据”这两种方法的隔阂,期望能够在连续空间里处理知识、语义,从而赋予计算机“认知马”的能力。

如何实现?有两种范式。范式一:所有的处理都在连续空间里进行。在连续向量空间中用数据驱动的方法不具有语义功能,原因还是在于前面提到的“局部特征”。我再举一个例子,如上图所示,计算机识别鸟,提取的特征来自“头部发白部分”,这种方法非常容易受到攻击,仅在“头部”用一些手段,就能让系统处理效率大大降低。
要克服这个问题必须在模型中融入知识。目前我的团队,以及瑞莱智慧都在这个方向上努力。基本思路是将知识放进空间向量中进行处理。其中知识的表示方法,我们在想办法用概率或者向量的方法表达出来,目的是想和原来的算法结合起来。

当前的一些相关进展是对抗训练,即用对抗样本训练系统,且能够告诉系统“虽然这个样本在某些局部特征上和鸟相同,但它并不是鸟,对抗样本不能识别为真正的样本”。因此,对抗训练能够在某种程度上赋予算法知识。
对抗训练也有局限性,如果换一种对抗样本,计算机或许还会犯同样的错误。为了解决这个问题,清华大学和瑞莱智慧合作,在贝叶斯深度学习上下功夫,尝试将先验知识、后验约束加上去,目前已经看到了非常好的效果。
其实,这也是现在全世界主要的工作思路,其优势在于能够发挥深度学习的威力。毕竟,深度学习有各种数学工具的优势,在处理连续向量空间上很有“天赋”。但这种方法基本上只能够针对某些特定条件、特定攻击,虽然计算机很擅长,但治标不治本,还有很长的路要走。
范式一的困难性在于:当知识转为向量表示形式时,丢失了大量语义,算法的鲁棒性提高并不多,因为关键是寻找更有效的“嵌入”方法。

因此,范式二“打通两个空间”的思路有可能从根本上解决问题。计算机在完成图像识别任务的时候,并没有进行图像分割。换句话说,计算机并不知道马在什么地方,也不知道何处有马。如果想要实现where和what,需要同时做马的识别和马的分割,目前这方面的工作还没有同时进行,因为“认识”和“分割”这两项工作都很难。
相比之下,人类又是如何识别马的?通过无监督学习。我们小的时候,尤其是一两岁以前,非常重要的任务是“无监督学习”,建立周围常见物体的模型,所以我们两岁以前有了狗和猫的模型,已经认识猫和狗,因此我们通过举一反三很容易建立起来马的模型,换句话讲我们所以能够识别马,就是因为我们早已认识马,我们大脑里面有马的模型。

如何在计算机里面建立模型?如何通过无监督的方法进行学习、鉴定?我的博士生做的一个工作是:想办法通过学习,把所有马的模型建立在隐变量里面,然后通过采样实现马的识别,实际上此模型是通过无监督学习或者预训练进行建立的。目前,用这个思路建立的模型,在完成分类、识别任务时候,效率大幅度提升。
不得不承认,这条路仍然非常艰巨。还拿马举例,因为物体是非刚性的,马有各种变形,躺下的马和跑起来的马在形状上大不相同。所以需要建立什么样的模型,是需要探讨的问题。
综上,范式二的本质困难在于两个方面,一是模型的表示,是采用确定性还是概率性的方式?二是模型的获取,是通过无监督还是强化学习?
发展第三代人工智能是一项非常长期的任务,人工智能的安全和治理也是长期的任务,安全问题是由算法本身引起,彻底解决有很长的路要走。
解决人工智能安全性问题必须两手抓,一手抓治理,治理不是短期的任务,是长期的任务;一手抓创新发展,创新发展要克服人工智能算法本身的不安全性,也是一个长期的任务。
“共倡宣言”为下一代人工智能保驾护航
为了更好地推动人工智能技术创新和产业稳健发展,形成更完备规范的创新体系和产业生态,《人工智能产业担当宣言》也在本次论坛上正式对外发布。

宣言由北京智源人工智能研究院、瑞莱智慧联合发起,百度、华为、蚂蚁集团、寒武纪、爱笔科技、第四范式、出门问问等人工智能行业的核心骨干企业、学术研究机构共同参与。
北京瑞莱智慧科技有限公司CEO田天作为论坛承办方与宣言核心参与方率先表示,让人工智能更好地服务于人类,是行业共同的目标,当整个社会重新审视技术的价值,科技从业者更应感受到科技治理的紧迫性和使命感,应当积极主动开展自治工作,同时开放共享,共举科技担当,将科技力量打造成为人工智能创新治理体系中的核心支撑。
宣言包含五项倡议,首先强调,人工智能系统的设计、研发、实施和推广应符合可持续发展理念,以促进社会安全和福祉为目标,以尊重人类尊严和权益为前提。其次在技术能力方面,提出要最大限度确保人工智能系统安全可信,提高鲁棒性及抗干扰性,要增强算法透明性和可解释性,同时保障各方权利和隐私,对用户数据提供充分的安全保障。
