当前人工智能大模型在决策链路和逻辑上仍具有天然不确定性。当语言大模型“信口开河”时,不能认为是出现了所谓的“自我意识”,而仅仅是技术缺陷使然。当前,比识别AI内容更重要的,是弥补第二代AI本身的安全缺陷。

站在“人类文明的十字路口”,AI何去何从?这是摆在人类面前的一道必答题。自去年底ChatGPT横空出世、5天突破百万用户以来,有关AI与人类未来的讨论愈演愈烈,从产业界到学界,至今尚无定论。
回望历史,科学技术的发展总是在反对和质疑声中一路前行,新技术总会伴随新风险,这一次为何更棘手?作为地球文明的主导者,我们似乎遇到了一个前所未有的挑战:以目前AI的发展速度,人类会否沦为硅基智慧演化的一个过渡阶段?这一次人人都是参与者,无人可以置身事外。
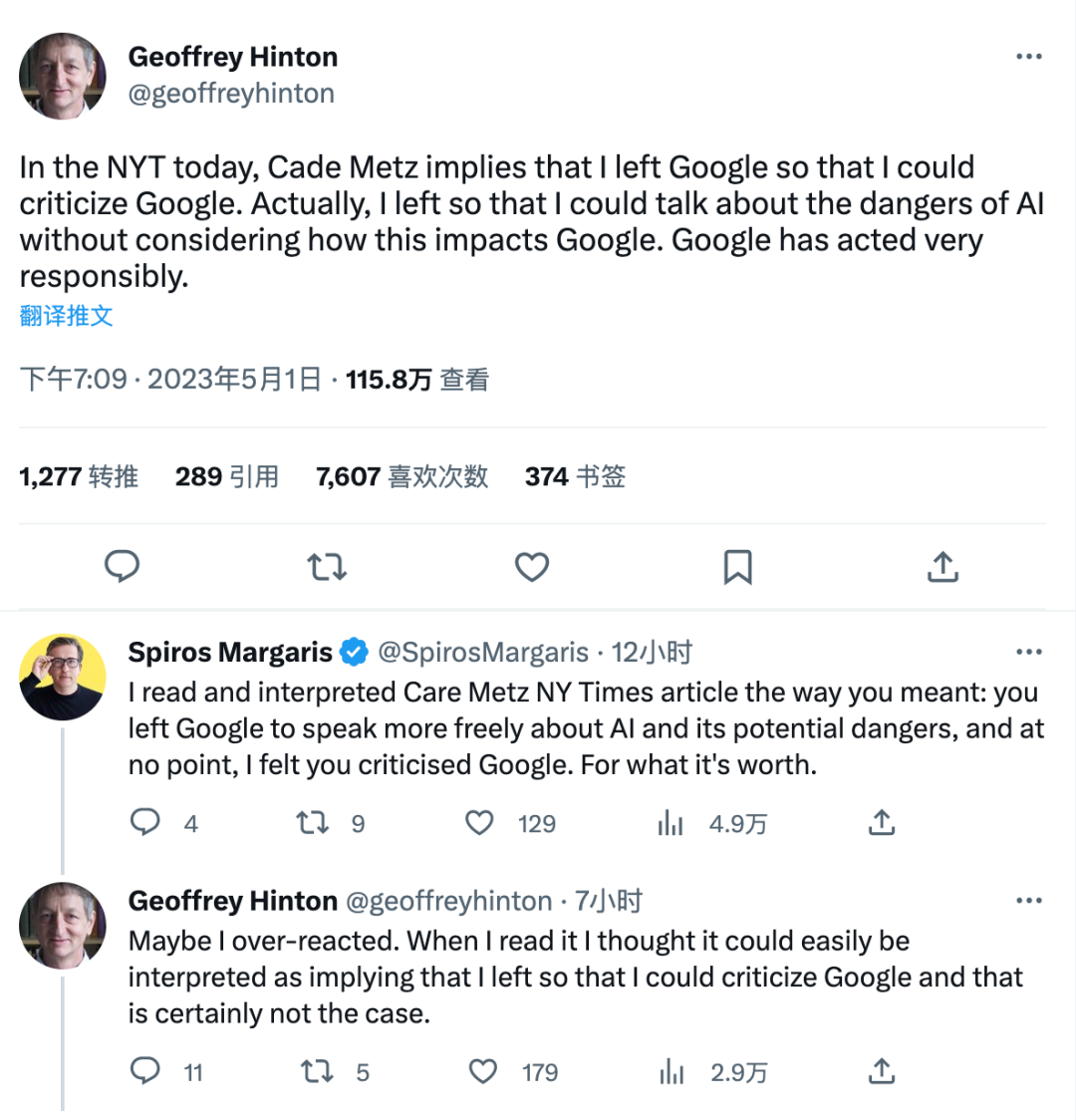
继全球千余名业界大佬公开签名呼吁暂停研发比GPT-4更强大的人工智能(AI)系统后,在业内有“AI教父”之称的计算机科学家杰弗里·辛顿(Geoffrey Hinton)本月初宣布离职谷歌,进一步加深了人们对AI是否已经失控的担忧。
 杰弗里·辛顿推特截图
杰弗里·辛顿推特截图
现年75岁的辛顿在神经网络领域长期从事开创性工作,为AI技术的发展奠定了基础。在3月下旬那封聚集了1000多个签名的公开信发布时,“深度学习三巨头”、三位2018年图灵奖得主表现各不相同。其中,蒙特利尔大学教授约书亚·本吉奥(Yoshua Bengio)高调签名,脸书首席人工智能科学家、纽约大学教授杨立昆(Yann LeCun)旗帜鲜明地反对,身为谷歌副总裁的辛顿一言未发。
宣布离职谷歌后,辛顿公开表达了自己的观点。他在接受《纽约时报》采访时表示,相较于气候变化,AI可能对人类的威胁“更紧迫”。他甚至表示,之所以离开谷歌,就是为了完全自由地说出AI潜在的风险,向世人提出警示。在5月3日麻省理工技术评论举行的一场半公开分享会上,辛顿坦言,过去他认为AI风险是遥不可及的,“但现在我认为这是严重的,而且相当近,但停止发展AI的想法太天真了。”
人类又一次陷入“科林格里奇困境”
人类历史上,曾无数次因新技术的诞生而产生担忧。比如,1863年瑞典化学家诺贝尔发明硝化甘油炸药,1885年德国人卡尔·本茨和戴姆勒发明内燃机汽车,20世纪40年代人类发明了原子弹……
辛顿如今对AI的情绪,与晚年时期的诺贝尔和爱因斯坦如出一辙。诺贝尔发明炸药原本是为了提高开矿、修路等工程的效率,当他发现自己的发明被投入到战场上后,其自责达到了顶点,这也促使他后来创立了诺贝尔奖。
清华大学人工智能国际治理研究院副院长梁正认为,在新技术兴起时,人类通常会面临所谓的“科林格里奇困境”——技术尚未出现,监管者无法提前预测其影响并采取行动;而当它已经出现时,采取行动往往为时已晚或成本过高。
幸运的是,迄今为止,人类通过不断适应新技术的发展而调整治理手段,一次次走出了“科林格里奇困境”。“比如在汽车大规模上市前,人们就为其安装上了刹车,之后也一直在完善汽车的安全性,为其提供各类检测和认证,甚至在汽车发明100多年后,人们还在为其安全‘打补丁’——装上安全气囊。”梁正说。
不过,他也承认,这一次AI的来势汹汹似乎与以往有些不同,“速度太快了。”比如,训练了几个月的ChatGPT的性能提升比过去几年迭代都要快,这意味着生成式AI大模型可以在几周内将潜在风险转变为实存风险,进而对人类社会造成不可估量的影响。
另一个不同是,这一次我们似乎无从下手。辛顿坦言,对于气候变化的风险,人类可以提出一些有效的应对策略,比如减少碳排放,“你相信这样做,最终一切都会好起来的。但对于AI的风险,你根本不知道如何下手。”
另外,商业竞争也会促使大模型一路“狂飙”。OpenAI深知GPT所蕴含的潜在风险,尽管他们对外表示将审慎推进AI系统的研发,但并不愿意就此暂停或彻底放慢脚步,而是期望社会为此做好准备。今年2月,这家公司刚刚公布了其发展通用AI的雄心与策略。而其首席执行官山姆·阿尔特曼表示,通用AI在AI技术上只能算是一个小节点,他们的远景目标是创造出远超人类智能的超级AI。
AI真的拥有人类智能了吗?
AI失控的故事,一直出现在科幻小说中。在大模型出现前,人们也对AI保持了相当警惕,但从未像今天一样如临大敌。那么,能识别出照片中的种种不合理、在各项考试中拿到高分、与人如沐春风般对话的大模型,真的已经拥有人类智能了吗?
联合国教科文组织AI伦理特设专家组专家、中国科学院自动化研究所AI伦理与治理中心主任曾毅认为,以ChatGPT为代表的大模型是“看似智能的信息处理”,与智能的本质没有关系。
“人们之所以觉得它很厉害,因为它的回答满足了人们的需求,如果这些回答来自于一个人,你会觉得他太聪明了。但如果你跟它说‘我很不高兴’,它说‘那我怎么能让你高兴一些’,这让人觉得它似乎理解了情感,而实际上它只是建立了文本之间的关联。”曾毅认为,目前的AI系统与人类智能的区别在于,大模型没有“我”的概念,没有自我就无法区分自我和他人,就无法换位思考,无法产生共情,也就无法真正理解情感。
北京瑞莱智慧科技有限公司AI治理研究院院长张伟强表示,当前的大模型仍属于第二代AI,其主要特征为以深度学习为技术、以数据驱动为模式。这使得它在决策链路和逻辑上具有天然的不确定性,即便是模型开发者,也无法准确预知模型的输出结果。当语言大模型“信口开河”时,不能认为是出现了所谓的“自我意识”,而仅仅是技术缺陷使然。
“计算能力当然是智能的一种,但智能的范围比这大得多,除了计算还有算计。”梁正说,如果把智能看作一个球体,阿尔法狗表现出的智力如同一个针尖般大小,大模型则是球体表面那一层,离真正的智慧内核还差得远。因此,许多技术派将ChatGPT视作某种“高科技鹦鹉”或人类知识库的映射。他们并不认为情况已经十分危急,因为与人类智能相比,大模型并没有触及认知的底层逻辑。
大模型真正的威胁在哪里?
我们应该允许机器充斥信息渠道传播谎言吗?应该将所有工作(包括那些让人有成就感的工作)都自动化吗?应该去开发可能最终超越甚至取代我们的非人类智慧吗?应该冒文明失控的风险吗?细读那封千人签名支持的公开信不难发现,业界大佬们并非为AI的智能即将超过人类而忧心忡忡,而是担心AI将消解人类存在的意义,解构人类社会的关系。
2017年,AI领域的重磅论文《一种采用自注意力机制的深度学习模型Transformer》发表,这个不到200行代码的模型开启了AI发展的新阶段。原本分属不同领域的计算机视觉、语音识别、图像生成、自然语言处理等技术开始融合。在Transformer的模型下,工程师利用互联网上的文本进行AI训练,训练方法是在一句话里删除一些单词,让模型试着预测缺失的单词或接下来的单词。除了文本,此模型也可应用于声音和图像。和单词一样,工程师可以将声音和图像分解成细小的模块,并利用修补模型进行预测和填补。
“所谓生成式AI,通俗来说就是让AI能够像人类一样说话、写字、画画,甚至分析和理解问题。”张伟强说,基于这种“创作”能力,“人工”与“非人工”的边界正在消弭,数字世界的信息真伪也越来越难以辨识。目前,已有聊天机器人被用来生成针对性的网络钓鱼邮件。不久的将来,当人们听到或看到家人的声音或图像时,或许首先要问自己一个问题:这是真的吗?毕竟,最新的AI技术只需3秒就能拷贝一个人的特征。
此外,生成式AI还带来了其他新风险的挑战。张伟强举例说,第一个风险就是加深“信息茧房”。过去,当我们搜索信息时,还能得到多种答案以供选择。语言大模型则更像一个“茧房”,你将如同《楚门的世界》中的男主角,被动接受模型世界给你的信息。
大模型带来的第二个新风险是对创新动能的干扰。人类总是会在思考的过程中迸发灵感,在动手的过程中有所收获,在不断试错的过程中走向成功,不少伟大的发明都是研究的“副产品”。而大模型提供了前往正确答案的直通车,人们将由此减少很多试错机会。正如刘慈欣在科幻作品《镜子》中描写的一种人类“结局”,人类因为从不犯错而走向灭亡。
我们为AI“套笼头”的速度并不慢
生成式AI的飞速发展,让人类社会面临着一场信任危机。当网络上充斥着越来越多不知真假的图片和视频,AI助手几秒钟就“洗”出了一篇像模像样的稿件,大批学生开始用ChatGPT写作业、写论文,我们是否有信心用好生成式AI这个工具?
对此,梁正比较乐观。他认为,新技术总是伴随着风险,而人类曾无数次处理过这种情况,因此不必太过担心。在他看来,人类应对这一波生成式AI的速度算得上及时。
去年11月30日,OpenAI推出ChatGPT。今年3月,英国政府发布了第一份AI白皮书,概述了AI治理的五项原则。3月底,意大利个人数据保护局(DPA)宣布从即日起禁止使用ChatGPT,限制OpenAI处理意大利用户信息数据,同时对其隐私安全问题立案调查。随后,德国、法国、爱尔兰等国家也开始准备效仿意大利的做法,加强对ChatGPT的监管。
在生成式AI的立法方面,中国与欧盟基本同步。4月11日,国家互联网信息办公室发布《生成式人工智能服务管理办法(征求意见稿)》。梁正认为,《管理办法》从三方面给生成式AI的发展戴上了“笼头”:一是大模型的数据来源要可靠;二是对AI生成的内容应履行告知义务;三是一旦造成损害,相关责任方需要承担责任。他建议,对生成式AI实行分级分类管理。比如,对某些高风险领域应该谨慎或严格控制使用生成式AI,而对一般的办公娱乐场合,只要标注出AI生成内容即可。
与其焦虑,不如用技术规制技术
如果把生成式AI比作“矛”,那么检测其安全性的公司就是“盾”。目前,在全球范围内,“盾”公司的数量并不多。由清华大学人工智能研究院孵化的瑞莱智慧(Real AI)就是一家“盾”公司,他们负责检测内容是否由AI生成,以及给大模型的安全系统“挑刺”。
“人类需要保持辨识信息真伪的能力,只要能识别出哪些内容是AI生成的,并精准告知公众,这项技术也没有那么可怕。”张伟强说,目前他们研发了一套AI内容识别系统,在识别能力上处于国际领先。
比识别AI内容更重要的,是弥补第二代AI本身的安全缺陷。张伟强解释说,AI的“智力”提高后,需要视其为社会生活中的一位新参与者。但第二代AI本身的运算过程是个“黑箱”,相当于你无法看透这位新伙伴的所思所想(可解释性差),且他还极易被欺骗犯错(鲁棒性差)。至今在大模型中无法彻底解决的“幻觉”问题就是由此产生,即使数据来源准确可靠,但大模型仍可能会“一本正经地胡说八道”。
不可否认,ChatGPT开启了一场全球范围的大模型“军备竞赛”,大厂纷纷发布各自的大模型系统,不少小公司也推出了基于自身领域的“小模型”。张伟强表示,市场的充分竞争固然有利于行业快速发展,但其先天的安全不足同样需要引起重视。比如,上个月,瑞莱智慧仅通过添加少量对抗样本,就让Meta发布的史上首个图像分割模型SAM失灵,显示出大模型在安全性方面仍然任重道远。
梁正认为,未来,当人们回望现在所经历的这个阶段,会清晰认识到AI的工具属性。为了保证它永远只是工具,我们必须及时跟进它的动向,敏捷治理,就像历史上人类曾经一贯为之的那样。
(作者:沈湫莎 责任编辑:任荃)
